Decodifica delle immagini uditive con l'analisi del modello multivoxel
Panoramica
Fonte: Laboratori di Jonas T. Kaplan e Sarah I. Gimbel—University of Southern California
Immagina il suono di una campana che suona. Cosa sta succedendo nel cervello quando evochiamo un suono come questo nell'"orecchio della mente"? Ci sono prove crescenti che il cervello usa gli stessi meccanismi per l'immaginazione che usa per la percezione. 1 Ad esempio, quando si immaginano immagini visive, la corteccia visiva si attiva e, quando si immaginano i suoni, la corteccia uditiva è impegnata. Tuttavia, fino a che punto queste attivazioni di cortecce sensoriali sono specifiche per il contenuto della nostra immaginazione?
Una tecnica che può aiutare a rispondere a questa domanda è l'analisi del modello multivoxel (MPVA), in cui le immagini cerebrali funzionali vengono analizzate utilizzando tecniche di apprendimento automatico. 2-3 In un esperimento MPVA, addestramo un algoritmo di apprendimento automatico per distinguere tra i vari modelli di attività evocati da stimoli diversi. Ad esempio, potremmo chiederci se immaginare il suono di una campana produce diversi modelli di attività nella corteccia uditiva rispetto all'immaginare il suono di una motosega o il suono di un violino. Se il nostro classificatore impara a distinguere i modelli di attività cerebrale prodotti da questi tre stimoli, allora possiamo concludere che la corteccia uditiva viene attivata in modo distinto da ogni stimolo. Un modo per pensare a questo tipo di esperimento è che invece di porre una domanda semplicemente sull'attività di una regione del cervello, facciamo una domanda sul contenuto informativo di quella regione.
In questo esperimento, basato su Meyer et al.,2010,4 suggeriremo ai partecipanti di immaginare diversi suoni presentando loro video silenziosi che potrebbero evocare immagini uditive. Poiché siamo interessati a misurare i modelli sottili evocati dall'immaginazione nella corteccia uditiva, è preferibile che gli stimoli siano presentati in completo silenzio, senza interferenze dai forti rumori fatti dallo scanner fMRI. Per raggiungere questo obiettivo, useremo un tipo speciale di sequenza MRI funzionale nota come campionamento temporale sparso. In questo approccio, un singolo volume fMRI viene acquisito 4-5 s dopo ogni stimolo, tempottico per catturare il picco della risposta emodinamica.
Procedura
1. Reclutamento dei partecipanti
- Recluta 20 partecipanti.
- I partecipanti dovrebbero essere destrimani e non avere una storia di disturbi neurologici o psicologici.
- I partecipanti dovrebbero avere una visione normale o corretta a normale per garantire che saranno in grado di vedere correttamente i segnali visivi.
- I partecipanti non dovrebbero avere metallo nel loro corpo. Questo è un importante requisito di sicurezza a causa dell'elevato campo magnetico coinvolto nella fMRI.
- I partecipanti non dovrebbero soffrire di claustrofobia, poiché la fMRI richiede di sdraiarsi nel piccolo spazio del foro dello scanner.
2. Procedure di pre-scansione
- Compila i documenti pre-scansione.
- Quando i partecipanti arrivano per la loro scansione fMRI, istruisci prima di compilare un modulo di schermo metallico per assicurarsi che non abbiano controindicazioni per la risonanza magnetica, un modulo di risultati incidentali che dà il consenso affinché la loro scansione sia esaminata da un radiologo e un modulo di consenso che dettaglia i rischi e i benefici dello studio.
- Prepara i partecipanti ad andare nello scanner rimuovendo tutto il metallo dal loro corpo, tra cui cinture, portafogli, telefoni, fermagli per capelli, monete e tutti i gioielli.
3. Fornire istruzioni per il partecipante.
- Dì ai partecipanti che vedranno una serie di diversi brevi video all'interno dello scanner. Questi video saranno silenziosi, ma potrebbero evocare un suono nell'orecchio della loro "mente". Chiedi al partecipante di concentrarsi e incoraggiare queste immagini uditive, per cercare di "sentire" il suono nel miglior modo possibile.
- Sottolinea al partecipante l'importanza di mantenere la testa ferma per tutta la scansione.
4. Metti il partecipante nello scanner.
- Dare ai partecipanti tappi per le orecchie per proteggere le orecchie dal rumore dello scanner e dei telefoni auricolari da indossare in modo che possano sentire lo sperimentatore durante la scansione e farli sdraiare sul letto con la testa nella bobina.
- Dare al partecipante la palla di spremimento di emergenza e istruirlo a spremerlo in caso di emergenza durante la scansione.
- Utilizzare cuscinetti di schiuma per fissare la testa dei partecipanti nella bobina per evitare movimenti eccessivi durante la scansione e ricordare al partecipante che è molto importante rimanere il più fermo possibile durante la scansione, poiché anche i più piccoli movimenti offuscano le immagini.
5. Raccolta dei dati
- Raccogli la scansione anatomica ad alta risoluzione.
- Avviare la scansione funzionale.
- Sincronizzare l'inizio della presentazione dello stimolo con l'avvio dello scanner.
- Per ottenere il campionamento temporale sparso, impostare il tempo di acquisizione di un volume MRI su 2 s, con un ritardo di 9 s tra le acquisizioni di volume.
- Presenta i video silenziosi tramite un laptop collegato a un proiettore. Il partecipante ha uno specchio sopra gli occhi, che riflette uno schermo sul retro del foro dello scanner.
- Sincronizza l'inizio di ogni clip video 5-s per iniziare 4 s dopo l'inizio dell'acquisizione MRI precedente. Ciò garantirà che il volume MRI successivo venga acquisito 7 s dopo l'inizio del video clip, per catturare l'attività emodinamica che corrisponde al centro del filmato.
- Presenta tre diversi video muti che evocano vivide immagini uditive: una campana che oscilla avanti e indietro, una motosega che taglia un albero e una persona che suona un violino.
- In ogni scansione funzionale, presenta ogni video 10 volte, in ordine casuale. Con ogni prova della durata di 11 s, ciò si tradurrà in una scansione lunga 330 s (5,5 min).
- Eseguire 4 scansioni funzionali.
6. Analisi dei dati
- Definire una regione di interesse (ROI).
- Utilizzare la scansione anatomica ad alta risoluzione di ciascun partecipante per tracciare i voxel che corrispondono alla corteccia uditiva precoce (Figura 1). Questo corrisponde alla superficie del lobo temporale, chiamato planum temporale. Usa le caratteristiche anatomiche del cervello di ogni persona per creare una maschera specifica per la loro corteccia uditiva.
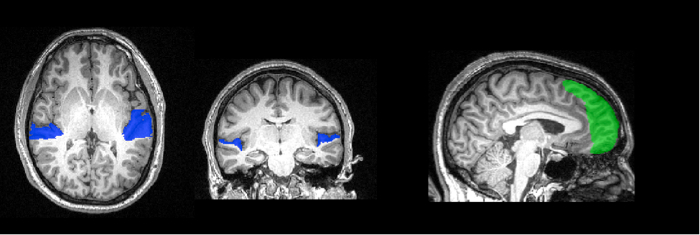
Figura 1: Tracciamento delle regioni di interesse. La superficie del planum temporale è stata tracciata sull'immagine anatomica ad alta risoluzione di questo partecipante ed è mostrata qui in blu. In verde è la maschera di controllo del polo frontale. Questi voxel saranno utilizzati per l'analisi MVPA.
- Pre-elaborare i dati.
- Eseguite la correzione del movimento per ridurre gli artefatti di movimento.
- Eseguire il filtraggio temporale per rimuovere le derive del segnale.
- Addestrare e testare l'algoritmo del classificatore.
- Dividere i dati in set di training e test. I dati di addestramento verranno utilizzati per addestrare il classificatore e i dati di test lasciati fuori saranno utilizzati per valutare ciò che ha appreso. Per massimizzare l'indipendenza dei dati di training e test, escludere i dati da una scansione funzionale come set di test.
- Addestrare un algoritmo support vector machine sui dati di addestramento etichettati dalla corteccia uditiva in ogni soggetto. Verificare la capacità del classificatore di indovinare correttamente l'identità del set di test senza etichetta e registrare l'accuratezza del classificatore.
- Ripetere questa procedura 4 volte, tralasciando ogni scansione come dati di test ogni volta. Questo tipo di procedura, in cui ogni sezione dei dati viene tralasciata una volta, è chiamata convalida incrociata.
- Combina le precisioni del classificatore attraverso le 4 pieghe di convalida incrociata facendo la media.
- Test statistici
- Per determinare se il classificatore sta ottenendo risultati migliori del caso (33%), possiamo confrontare i risultati a livello di gruppo con il caso. Per fare ciò, raccogliere le precisioni per ciascun soggetto e verificare che la distribuzione sia diversa dal caso utilizzando un test Wilcoxon Signed-Rank non parametrico.
- Possiamo anche chiederci se il classificatore sta funzionando meglio del caso per ogni individuo. Per determinare la probabilità di un determinato livello di accuratezza nei dati casuali, creare una distribuzione null addestrando e testando l'algoritmo MVPA su dati le cui etichette sono state mescolate in modo casuale. Permutare le etichette 10.000 volte per creare una distribuzione nulla dei valori di accuratezza e quindi confrontare il valore di accuratezza effettivo con questa distribuzione.
- Per dimostrare la specificità delle informazioni all'interno della corteccia uditiva, possiamo addestrare e testare il classificatore su voxel da una posizione diversa nel cervello. Qui, useremo una maschera del polo frontale, presa da un atlante probabilistico e deformata per adattarsi al cervello individuale di ciascun soggetto.
Risultati
L'accuratezza media del classificatore nel planum temporale in tutti i 20 partecipanti è stata del 59%. Secondo il test Wilcoxon Signed-Rank, questo è significativamente diverso dal livello di probabilità del 33%. La prestazione media nella maschera del polo frontale è stata del 32,5%, che non è maggiore del caso (Figura 2).

Figura 2. Prestazioni di classificazione in ciascun partecipante. Per la classificazione a tre vie, la prestazione casuale è del 33%. Secondo un test di permutazione, il livello alfa di p < 0,05 corrisponde al 42%.
Il test di permutazione ha rilevato che solo il 5% delle permutazioni ha raggiunto una precisione superiore al 42%; quindi, la nostra soglia statistica per i singoli soggetti è del 42%. Diciannove dei 20 soggetti avevano prestazioni del classificatore significativamente maggiori della possibilità di usare i voxel dal planum temporale, mentre nessuno aveva prestazioni maggiori del caso usando i voxel dal polo frontale.
Pertanto, siamo in grado di prevedere con successo dai modelli di attività nella corteccia uditiva quale dei tre suoni il partecipante stava immaginando. Non siamo stati in grado di fare questa previsione basata su modelli di attività dal polo frontale, suggerendo che l'informazione non è globale in tutto il cervello.
Applicazione e Riepilogo
MVPA è uno strumento utile per capire come il cervello rappresenta le informazioni. Invece di considerare il corso temporale di ciascun voxel separatamente come in un'analisi di attivazione tradizionale, questa tecnica considera i modelli su molti voxel contemporaneamente, offrendo una maggiore sensibilità rispetto alle tecniche univariate. Spesso un'analisi multivariata scopre differenze in cui una tecnica univariata non è in grado di farlo. In questo caso, abbiamo imparato qualcosa sui meccanismi delle immagini mentali sondando il contenuto delle informazioni in un'area specifica del cervello, la corteccia uditiva. La natura specifica del contenuto di questi modelli di attivazione sarebbe difficile da testare con approcci univariati.
Ci sono ulteriori vantaggi che derivano dalla direzione dell'inferenza in questo tipo di analisi. In MVPA iniziamo con modelli di attività cerebrale e tentiamo di dedurre qualcosa sullo stato mentale del partecipante. Questo tipo di approccio di "lettura del cervello" può portare allo sviluppo di interfacce cervello-computer e può consentire nuove opportunità di comunicazione con coloro che hanno problemi di parola o movimento.
Riferimenti
- Kosslyn, S.M., Ganis, G. & Thompson, W.L. Neural foundations of imagery. Nat Rev Neurosci 2, 635-642 (2001).
- Haynes, J.D. & Rees, G. Decoding mental states from brain activity in humans. Nat Rev Neurosci 7, 523-534 (2006).
- Norman, K.A., Polyn, S.M., Detre, G.J. & Haxby, J.V. Beyond mind-reading: multi-voxel pattern analysis of fMRI data. Trends Cogn Sci 10, 424-430 (2006).
- Meyer, K., et al. Predicting visual stimuli on the basis of activity in auditory cortices. Nat Neurosci 13, 667-668 (2010).
Vai a...
Video da questa raccolta:

Now Playing
Decodifica delle immagini uditive con l'analisi del modello multivoxel
Neuropsychology
6.4K Visualizzazioni

Sindrome da disconnessione interemisferica
Neuropsychology
68.2K Visualizzazioni

Mappe motorie
Neuropsychology
27.5K Visualizzazioni

Prospettive sulla neuropsicologia
Neuropsychology
12.0K Visualizzazioni

Processo decisionale e l'Iowa gambling task
Neuropsychology
32.4K Visualizzazioni

Funzione esecutiva nel disturbo dello spettro autistico
Neuropsychology
17.7K Visualizzazioni

Amnesia anterograda
Neuropsychology
30.3K Visualizzazioni

Correlazioni fisiologiche del riconoscimento delle emozioni
Neuropsychology
16.2K Visualizzazioni

I potenziali evento-correlati e il paradigma dell'odd-ball
Neuropsychology
27.4K Visualizzazioni

Linguaggio: l'N400 nell'incongruenza semantica
Neuropsychology
19.6K Visualizzazioni

Apprendimento e memoria: la procedura ricorda-conosci
Neuropsychology
17.1K Visualizzazioni

Misurazione delle differenze di materia grigia con la morfometria basata su voxel: il cervello musicale
Neuropsychology
17.3K Visualizzazioni

Attenzione visiva: indagine fMRI del controllo attentivo basato sugli oggetti
Neuropsychology
41.5K Visualizzazioni

Utilizzo dell'imaging con tensore di diffusione nelle lesioni cerebrali traumatiche
Neuropsychology
16.7K Visualizzazioni

Utilizzo della stimolazione magnetica transcranica (TMS) per la misurazione dell'eccitabilità della corteccia motoria durante l'osservazione di un'azione
Neuropsychology
10.1K Visualizzazioni
Personale delle biblioteche
Copyright © 2025 MyJoVE Corporation. Tutti i diritti riservati