
Apprendimento statistico visivo
Panoramica
Fonte: Laboratorio di Jonathan Flombaum—Johns Hopkins University
L'ambiente visivo contiene enormi quantità di informazioni che coinvolgono le relazioni tra oggetti nello spazio e nel tempo; alcuni oggetti hanno maggiori probabilità di apparire in prossimità di altri oggetti. L'apprendimento di queste regolarità può supportare una vasta gamma di elaborazioni visive, incluso il riconoscimento degli oggetti. Non sorprende quindi che gli esseri umani sembrino imparare queste regolarità automaticamente, rapidamente e senza consapevolezza cosciente. Il nome di questo tipo di apprendimento implicito è apprendimento statistico visivo. In laboratorio, viene studiato con un paradigma di codifica incidentale: i partecipanti osservano un flusso di oggetti senza senso e completano un compito di copertura, un compito non correlato alla struttura statistica sottostante nel flusso. Ma la struttura statistica è presente, e dopo un breve periodo di esposizione – breve come 10 minuti in alcuni esperimenti – un test di familiarità rivela la portata dell'apprendimento da parte dei partecipanti.
Questo video dimostrerà i metodi standard per indurre e testare l'apprendimento statistico visivo.
Procedura
1. Genera una serie di oggetti senza senso e disponili in una struttura tripletta.
- Spesso l'apprendimento statistico visivo viene studiato con oggetti semplici come il set qui sotto. Generare un insieme di oggetti e quindi raggrupparli in terzine (Figura 1).

Figura 1. Stimoli campione raggruppati in terzine per l'apprendimento statistico visivo. Nel segmento di apprendimento di un esperimento, le terzine appariranno in ordine casuale, ma gli elementi all'interno di una tripletta appariranno sempre in ordine, con l'elemento a sinistra che apparirà per primo seguito successivamente dagli elementi alla sua destra.
2. Sequenziare l'esperimento.
- Sequenzia l'esperimento con software come e-Prime o utilizzando una libreria di routine come Psychophysics Toolbox in MATLAB o PsycoPy per Python.
- Gli oggetti senza senso vengono visualizzati al centro dello schermo, uno alla volta, per 250 ms ciascuno.
- Istruire il programma a mostrare sempre i membri di una tripletta in sequenza e a scegliere quale tripletta mostrare successivamente in modo casuale, finendo con sequenze simili alla Figura 2.

Figura 2. Sequenza di apprendimento di esempio per l'apprendimento statistico visivo. Le terzine appaiono in un ordine casuale tale che la probabilità di transizione per gli elementi in sequenze diverse è di circa 0,33, mentre la probabilità di transizione all'interno di una sequenza è 1. - Si noti che, poiché le terzine appaiono sempre in sequenza, la probabilità di transizione tra gli elementi di una tripletta è sempre 1. Ma poiché le transizioni tra triplette sono selezionate in modo casuale, le probabilità di transizione tra elementi non correlati sono considerevolmente più basse, di solito inventate per essere circa 0,33.
- Infine, costruisci un'attività di copertura. Indicare al programma di eseguire il rendering di uno degli oggetti in ROSSO, anziché in grigio. Il programma lo farà circa 20 volte nel corso di un esperimento di 10 minuti, selezionando i momenti in modo casuale. Il compito del partecipante sarà quello di premere un tasto ogni volta che un oggetto viene mostrato in grigio, ma di trattenere una risposta ogni volta che è rosso. Questo li manterrà impegnati negli stimoli.
3. Test di familiarità
- Scrivere un programma separato per il test di familiarità. In ogni prova del test, il programma seleziona casualmente una delle terzine effettive e genera casualmente una nuova tripletta dai costituenti delle terzine effettive. Queste terzine generate casualmente sono chiamate "lamine".
- Vengono visualizzati fianco a fianco e il partecipante deve indicare quale è più familiare premendo un tasto.
- L'esperimento dovrebbe includere circa 30 prove di test di familiarità.
- Le istruzioni per il test di familiarità sono importanti. Devono includere qualcosa del genere: "Vorrei che tu facessi un altro compito prima che l'esperimento sia finito. Dovrebbero volerci solo cinque minuti. Probabilmente non l'hai notato, ma nella sequenza di forme che hai appena visto, alcune forme avevano maggiori probabilità di apparire dopo altre. Ora ti mostrerò due serie di forme dall'esperimento e devi solo premere il tasto 1 o il tasto 2 per farmi sapere quale raggruppamento ti sembra più familiare. Potresti non sentire di riconoscere neanche. In tutte le prove, voglio che tu vada con il tuo istinto e indovini se devi".
L'apprendimento delle regolarità - le strutture statistiche degli oggetti nel nostro mondo esterno - è una parte importante dell'elaborazione visiva.
Gli oggetti nel nostro ambiente visivo si verificano nelle dimensioni dello spazio e del tempo. Alcuni oggetti hanno maggiori probabilità di apparire vicino ad altri, come una tazza di caffè accanto a un computer.
Tali eventi forniscono regolarità che supportano il riconoscimento prevedibile degli oggetti, in cui gli esseri umani imparano automaticamente e rapidamente, senza consapevolezza cosciente.
Questo video illustra come impostare e condurre un esperimento di apprendimento statistico visivo utilizzando un paradigma di codifica incidentale, nonché come analizzare i dati e interpretare i risultati.
In questo esperimento, gli stimoli - insiemi di oggetti senza senso raggruppati in terzine - vengono visualizzati al centro dello schermo di un computer, uno alla volta, per 250 ms ciascuno.
Per stabilire le regolarità - la struttura statistica - gli oggetti all'interno di una tripletta sono sempre mostrati nella stessa sequenza, ma l'ordine delle terzine è presentato a caso.
Pertanto, la probabilità di transizione tra gli elementi di una data tripletta è sempre 1, mentre le probabilità di transizione tra elementi non correlati sono considerevolmente inferiori.
Per esporre inconsapevolmente i partecipanti alle sequenze di oggetti, viene utilizzata un'attività di copertura con oggetti colorati. In questo caso, ai partecipanti viene chiesto di rispondere quando gli oggetti sono grigi e di trattenere quando gli oggetti appaiono casualmente rossi.
Una volta completata l'attività di copertura, ai partecipanti viene assegnato un compito di familiarità per testare l'estensione della codifica degli oggetti senza senso precedenti. Durante ogni prova di familiarità, le terzine viste in precedenza vengono presentate in modo casuale insieme alle terzine appena generate, denominate pellicole.
Ora, ai partecipanti viene chiesto di identificare quale set è più familiare. La variabile dipendente è quindi il numero di volte in cui i partecipanti identificano correttamente le terzine precedenti come le più familiari, piuttosto che le pellicole.
Se non si verifica alcun apprendimento durante la fase di codifica iniziale, le terzine effettive e di lamina verrebbero raccolte lo stesso numero di volte. D'altra parte, se l'apprendimento si è verificato, le terzine effettive saranno raccolte più frequentemente delle pellicole.
Prima dell'arrivo del partecipante, verificare che siano stati generati gli stimoli e i parametri di codifica da utilizzare.
Per iniziare l'esperimento, salutare il partecipante in laboratorio e spiegare le procedure generali che verranno utilizzate per il compito.
Fare in modo che il partecipante si sieda comodamente davanti al monitor e alla tastiera del computer. Spiega che quando un oggetto grigio appare sullo schermo dovrebbero premere il tasto 'J' e quando appaiono oggetti rossi dovrebbero trattenere le risposte.
Una volta che il partecipante ha compreso le regole del compito, avviare la prima parte dell'esperimento, la fase di codifica incidentale. Esporre i partecipanti alle sequenze di oggetti per 10 minuti.
Dopo il breve periodo di esposizione, spiega che c'è un altro compito da completare in un periodo di 5 minuti. Istruisci il partecipante che ora vedrà due serie di terzine e dovrebbe premere il tasto 1 o il tasto 2 per indicare quale raggruppamento sembra più familiare. Dì loro che dovrebbero indovinare se non riconoscono neanche.
Dopo aver confermato che il partecipante è pronto per iniziare, inizia le 30 prove di familiarità.
Per analizzare i dati nella fase di familiarità, segnare ogni prova in cui il partecipante ha scelto la tripletta familiare come corretta e la tripletta di lamina come errata.
Per visualizzare i risultati, rappresentare graficamente la media delle risposte corrette percentuali tra i partecipanti. Poiché le prestazioni casuali sono del 50%, si noti che l'apprendimento statistico visivo si è verificato, poiché i partecipanti hanno identificato correttamente gli oggetti familiari circa il 70% delle volte.
Ora che hai familiarità con i metodi per indurre e testare l'apprendimento statistico visivo, diamo un'occhiata ad altri modi in cui gli psicologi sperimentali usano le statistiche per indagare sull'apprendimento.
Il paradigma può essere tradotto in classi più ampie di meccanismi di apprendimento sensoriale che includono il dominio uditivo. Ad esempio, neonati e bambini usano la statistica uditiva nella formazione linguistica precoce perché i suoni e le lettere in una lingua tendono ad apparire con relazioni statistiche altamente affidabili.
In un altro esperimento, i ricercatori hanno studiato come le associazioni tra lettere e colori possano essere apprese inconsapevolmente o implicitamente. Per diversi giorni, i partecipanti hanno letto testi personalizzati per avere quattro lettere distintamente colorate.
Quando è stato chiesto di identificare il colore delle lettere presentate su uno schermo, i partecipanti sono stati più veloci e precisi per le coppie lettera-colore che erano le stesse del testo personalizzato. Ciò suggerisce che la struttura statistica delle lettere colorate è stata implicitamente appresa.
Hai appena visto l'introduzione di JoVE all'apprendimento statistico visivo. Ora dovresti avere una buona comprensione di come impostare ed eseguire l'esperimento, oltre ad analizzare e valutare i risultati.
Grazie per l'attenzione!
Risultati
Poiché ogni test di familiarità include una tripletta e una lamina (una non tripletta generata casualmente), le prestazioni di probabilità complessive sono del 50%. Segna ogni prova in termini di se il partecipante ha scelto la tripletta o la lamina come più familiare, e la selezione delle terzine più della metà delle volte costituisce una dimostrazione dell'apprendimento statistico. Dopo aver testato 10-20 partecipanti, media insieme il tasso di scelta della tripletta familiare tra tutti i partecipanti. Un semplice grafico a barre è un buon modo per visualizzare l'effetto principale (Figura 3).
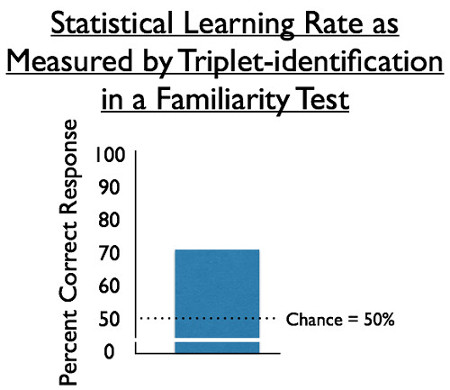
Figura 3. Tasso di apprendimento statistico misurato mediante identificazione tripletta in un test di familiarità. Il 50% è la prestazione casuale, uguale familiarità sia con le terzine che con i foil.
Applicazione e Riepilogo
L'apprendimento statistico visivo è stato utilizzato come punto di partenza per indagare una varietà di problemi nell'apprendimento, nella percezione e nella memoria. Questi includono l'influenza e la necessità di attenzione per l'apprendimento, le aree cerebrali coinvolte nella memoria visiva implicita e nel riconoscimento degli oggetti, nonché le differenze e le somiglianze nell'apprendimento della struttura spaziale rispetto a quella temporale. Si pensa anche che l'apprendimento statistico visivo sia un esempio di una classe più ampia di meccanismi di apprendimento statistico, compresa la statistica uditiva, che si pensa supporti l'apprendimento precoce delle lingue nei neonati e nei bambini perché i suoni e le lettere in una lingua tendono ad apparire con relazioni statistiche altamente affidabili.
Vai a...
Video da questa raccolta:

Now Playing
Apprendimento statistico visivo
Cognitive Psychology
7.2K Visualizzazioni

Ascolto dicotico
Cognitive Psychology
26.7K Visualizzazioni

Misurazione del tempo di reazione e metodo sottrattivo di Donders
Cognitive Psychology
44.4K Visualizzazioni

Ricerca visiva di caratteristiche e congiunzioni
Cognitive Psychology
26.9K Visualizzazioni

Prospettive sulla psicologia cognitiva
Cognitive Psychology
7.0K Visualizzazioni

Rivalità binoculare
Cognitive Psychology
8.0K Visualizzazioni

Monitoraggio di oggetti multipli
Cognitive Psychology
7.8K Visualizzazioni

Test sensoriale del numero approssimato
Cognitive Psychology
7.6K Visualizzazioni

Rotazione mentale
Cognitive Psychology
13.2K Visualizzazioni

Teoria del prospetto
Cognitive Psychology
11.2K Visualizzazioni

Misurare l'ampiezza della memoria di lavoro verbale
Cognitive Psychology
12.6K Visualizzazioni

La precisione della memoria di lavoro visiva con la stima ritardata
Cognitive Psychology
5.2K Visualizzazioni

Il priming di uno stimolo verbale
Cognitive Psychology
15.1K Visualizzazioni

Apprendimento accidentale
Cognitive Psychology
8.6K Visualizzazioni

Apprendimento motorio nel disegno speculare
Cognitive Psychology
55.6K Visualizzazioni
Personale delle biblioteche
Copyright © 2025 MyJoVE Corporation. Tutti i diritti riservati